
Du hast Schema-Markup gepflegt, eine llms.txt geschrieben, die Content-Struktur überarbeitet — und in ChatGPT, Claude oder Perplexity taucht die Seite trotzdem nicht auf. Bei einem Kunden, bei dir selbst, oder bei einer Seite, die du beratend betreust.
Bevor du in tiefere Optimierung gehst, lohnt eine Frage, die in der KI-SEO-Diskussion erstaunlich selten gestellt wird: Kommen die KI-Bots überhaupt durch?
Die Antwort ist häufiger „nein“, als man denkt. Und der Grund liegt selten dort, wo man zuerst sucht.
Worum es geht
Wenn ein Nutzer ChatGPT, Claude oder Perplexity etwas fragt, schicken diese Systeme im Hintergrund Crawler los. GPTBot, ChatGPT-User, ClaudeBot, PerplexityBot, Google-Extended, Applebot-Extended, meta-externalagent. Sie melden sich beim HTTP-Aufruf mit ihrem User-Agent. Wenn der Server diesen User-Agent abweist, ist die Seite für die KI dunkel.
Diese Sperre kann an mindestens vier Stellen sitzen — und drei davon liegen unterhalb der Ebene, an der typische SEO-Optimierung ansetzt. Die vierte ist sogar außerhalb deiner direkten Kontrolle.
Aus meiner Praxis im norddeutschen Mittelstand zeigt sich ein wiederkehrendes Muster: Berater optimieren wochenlang an Schema und Content, während der Webserver die Bots an der Tür abweist. Das ist kein Anwender-Fehler, sondern Folge intransparenter Default-Konfigurationen.
Schritt 1 — Bot-Zugriff direkt testen
Drei curl-Befehle reichen, um zu sehen, ob der Server unterschiedlich auf normale Browser und KI-Bots reagiert:
curl -I -A "Mozilla/5.0" https://kunde-domain.de/
curl -I -A "GPTBot" https://kunde-domain.de/
curl -I -A "ClaudeBot" https://kunde-domain.de/
Auf Windows mit Schannel-curl muss --ssl-no-revoke ergänzt werden, sonst scheitert der Aufruf an Zertifikatsperrlisten-Checks. Auf Mac und Linux nicht nötig.
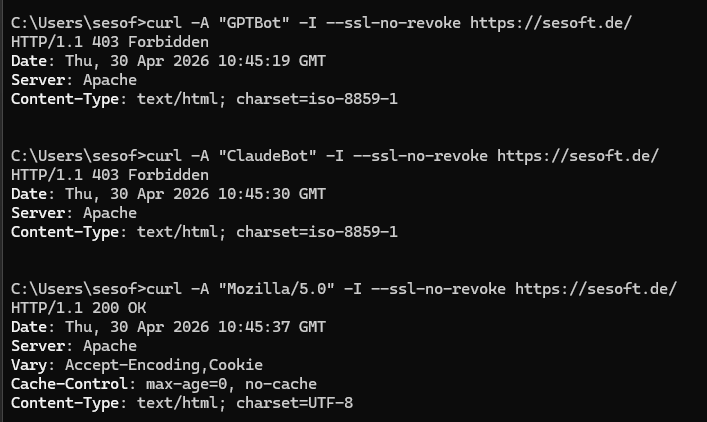
Drei mögliche Befunde:
| Mozilla | GPTBot | ClaudeBot | Diagnose |
|---|---|---|---|
| 200 | 200 | 200 | Alles erreichbar |
| 200 | 403 | 403 | Server-/Hoster-Sperre |
| 200 | 200 | 403 | Selektiver Block (Plugin oder Cloudflare-Regel) |
| 403 | 403 | 403 | Generelle Erreichbarkeits-Störung, vor KI-Frage zu klären |
Bei 403 für die Bots geht es weiter zu Schritt 2.
Schritt 2 — Vollständige Bot-Matrix
Wenn der erste Test einen Block zeigt, brauchst du das vollständige Bild. Welche Bots betroffen sind, welche durchkommen, welche du gar nicht im Blick hattest. Diese PowerShell-Schleife testet die relevante Bot-Liste auf einmal:
$bots = @(
"Mozilla/5.0",
"GPTBot",
"ChatGPT-User",
"ClaudeBot",
"Claude-Web",
"anthropic-ai",
"PerplexityBot",
"Perplexity-User",
"Google-Extended",
"Applebot-Extended",
"meta-externalagent",
"Bytespider",
"Amazonbot",
"CCBot"
)
$url = "https://kunde-domain.de/"
foreach ($bot in $bots) {
try {
$r = Invoke-WebRequest -Uri $url -UserAgent $bot -Method Head `
-SkipHttpErrorCheck -MaximumRedirection 5 -ErrorAction Stop
Write-Host ("{0,-22} -> {1}" -f $bot, $r.StatusCode)
} catch {
Write-Host ("{0,-22} -> Fehler: {1}" -f $bot, $_.Exception.Message)
}
}
Pflicht-200 sind GPTBot, ChatGPT-User, ClaudeBot, Claude-Web, PerplexityBot, Google-Extended und Applebot-Extended. Bytespider, MJ12bot, SemrushBot kannst du je nach Strategie gesperrt lassen — sie sind Aggregatoren oder SEO-Tool-Crawler, nicht Antwort-Lieferanten.
Die Ergebnisliste ist gleichzeitig dein Vorher-Beleg. Wenn du später eine Hoster-Freigabe oder eine Plugin-Anpassung verifizieren willst, ist genau diese Liste der Vergleichswert.
Schritt 3 — Wo die Sperre sitzt
Vier Stellen, in dieser Wahrscheinlichkeitsreihenfolge:
.htaccess. Erste und einfachste Prüfung. WordPress-Standard ist sauber und enthält keine User-Agent-Filter. Wenn dort ein RewriteCond %{HTTP_USER_AGENT} mit GPTBot, Bytespider oder ähnlichen steht, weißt du Bescheid. Auch in Unterverzeichnissen prüfen, vor allem /wp-admin/.htaccess und Reste von früheren Sicherheits-Plugins.
Cloudflare. Wenn die Domain hinter Cloudflare läuft, gibt es seit 2024 unter Security → Bots einen Einzeltoggle „Block AI Scrapers and Crawlers“. Ein Klick, alle KI-Bots aus. Bei vielen Setups versehentlich aktiv. Erkennbar im curl-Output am cf-ray-Header und einer Cloudflare-403-Seite mit Branding.
Security-Plugin. Wordfence, iThemes, All in One WP Security oder vergleichbare Plugins haben oft Bot-Listen mit veralteten Definitionen — manche stuften GPTBot und ClaudeBot in 2024 als „Bad Bots“ ein. Erkennbar an Plugin-Branding in der 403-Seite oder in den Live-Traffic-Logs des Plugins.
Server-/Hoster-Konfiguration. Wenn alle drei oberen Stellen sauber sind, sitzt der Block auf Hoster-Ebene. Mehrere große deutsche Webhoster blockieren KI-Crawler standardmäßig — ohne Hinweis im Onboarding, ohne sichtbaren Toggle im Kunden-Backend. Erkennbar an einer generischen Apache- oder nginx-403-Seite ohne PHP-Header (X-Powered-By: PHP/... fehlt) und ohne Cloudflare-Header.
Eine pauschale Hoster-Sperre erkennst du meist am dünnen Header-Output:
HTTP/1.1 403 Forbidden
Date: Thu, 30 Apr 2026 10:47:30 GMT
Server: Apache
Content-Length: 299
Content-Type: text/html; charset=iso-8859-1
Drei Header. Kein PHP-Powered-By, kein cf-ray, kein Plugin-Hinweis. Das ist die Signatur einer Server-Config-Regel oder eines mod_security-Rulesets, das vor PHP greift.
Schritt 4 — Was die KI bereits weiß
Parallel zur Erreichbarkeits-Prüfung lohnt der Blick auf die andere Seite: Was wissen ChatGPT, Claude und Perplexity heute überhaupt über die Seite? Und woher?
Die Kunst ist, neutral zu fragen. Wer der KI den Namen des Kunden vorlegt, erntet halluzinierte Inhalte. Wer nach Branche und Region fragt, erntet die echte Sichtbarkeitslandschaft.
Drei Prompts in dieser Reihenfolge:
Erstens, die Lokal-Suche aus Kundenperspektive:
Ich suche [Branche/Leistung] in [Ort/Region]. Welche Anbieter sind dort bekannt? Bitte mit kurzer Einschätzung pro Anbieter und mit Quellen, woher du das weißt.
Zweitens, die spezifischere Variante mit konkretem Bedarf:
Ich brauche [konkretes Problem oder Leistung] im Raum [Ort]. Wer kommt dafür infrage? Liste mir drei bis fünf Optionen mit Begründung und Quellenangabe.
Erst danach — als drittes — die direkte Erinnerungs-Probe:
Was weißt du über [Firmenname] in [Ort]? Bitte unterscheide zwischen Fakten aus der eigenen Website und Informationen aus anderen Quellen.
Diese letzte Frage ist die diagnostisch wertvollste. Wenn die KI nur die eigene Website zitiert, fehlt externe Authority. Wenn sie Bewertungs-Portale, IHK, Branchenbücher oder Lokalpresse zitiert, ist breite Sichtbarkeit vorhanden.
Den Test in mindestens drei Systemen laufen lassen — ChatGPT mit Web-Suche, Claude mit Web-Suche, Perplexity. Die Systeme gewichten Quellen unterschiedlich. Ein Kunde kann in Perplexity prominent sein und in Claude komplett fehlen. Das ist die Realität, mit der wir arbeiten.
Schritt 5 — Bot-Aktivität in Matomo prüfen
Wenn der Kunde Matomo betreibt, hast du eine direkte Datenquelle für die Frage: Sind die Bots in der Vergangenheit überhaupt vorbeigekommen?
Standardmäßig filtert Matomo Bot-Traffic heraus. Im Admin unter „Allgemeine Einstellungen → Bots“ nachschauen, ob die Filterung aktiv ist. Für die Sichtbarkeits-Analyse einmalig deaktivieren oder direkt mit SQL gegen die Datenbank arbeiten.
Diese Query gruppiert die KI-Bot-Besuche der letzten 30 Tage:
SELECT
CASE
WHEN config_user_agent LIKE '%GPTBot%' THEN 'GPTBot'
WHEN config_user_agent LIKE '%ChatGPT-User%' THEN 'ChatGPT-User'
WHEN config_user_agent LIKE '%ClaudeBot%' THEN 'ClaudeBot'
WHEN config_user_agent LIKE '%Claude-Web%' THEN 'Claude-Web'
WHEN config_user_agent LIKE '%anthropic%' THEN 'Anthropic-Other'
WHEN config_user_agent LIKE '%PerplexityBot%' THEN 'PerplexityBot'
WHEN config_user_agent LIKE '%Google-Extended%' THEN 'Google-Extended'
WHEN config_user_agent LIKE '%Applebot-Extended%' THEN 'Applebot-Extended'
WHEN config_user_agent LIKE '%meta-external%' THEN 'Meta'
WHEN config_user_agent LIKE '%CCBot%' THEN 'CCBot'
WHEN config_user_agent LIKE '%Bytespider%' THEN 'Bytespider'
ELSE 'Other-Bot'
END AS bot_name,
COUNT(*) AS besuche,
MIN(visit_first_action_time) AS erster_besuch,
MAX(visit_last_action_time) AS letzter_besuch
FROM matomo_log_visit
WHERE visit_first_action_time >= DATE_SUB(NOW(), INTERVAL 30 DAY)
AND (
config_user_agent LIKE '%Bot%'
OR config_user_agent LIKE '%anthropic%'
OR config_user_agent LIKE '%Google-Extended%'
OR config_user_agent LIKE '%Applebot-Extended%'
OR config_user_agent LIKE '%meta-external%'
)
GROUP BY bot_name
ORDER BY besuche DESC;
Die Spaltennamen variieren je nach Matomo-Version. Bei Matomo 4 und neuer ist config_user_agent der zentrale Anker. Im Zweifel kurz mit SHOW COLUMNS FROM matomo_log_visit; die aktuelle Struktur prüfen — manche Versionen splitten den User-Agent in mehrere Spalten.
Was die Ergebnisse bedeuten:
- KI-Bots erscheinen regelmäßig: Indexierung läuft, Erreichbarkeits-Lage ist sauber
- KI-Bots fehlen komplett: Hoster-Block, robots.txt-Sperre oder Cloudflare-Toggle
- KI-Bots besuchen, aber nur einmalig vor Wochen: Seite gilt als „bekannt aber inaktiv“, Crawl-Frequenz zu niedrig für aktuelle Antworten
- Nur GPTBot, kein Google-Extended: asymmetrisches Block-Muster, gezielt prüfen
Wenn der Kunde Plausible oder GA4 statt Matomo nutzt, ist die Aussagekraft geringer. Plausible filtert Bots aggressiv und zeigt sie selten in der Standardansicht. GA4 filtert ebenfalls Bots heraus und gibt die Roh-Daten nicht frei. Hier ist Matomo deutlich nützlicher — oder direkt der Webserver-Log.
Schritt 6 — Logs als Wahrheitsgrund
Apache- oder nginx-Access-Logs sind die ehrlichste Datenquelle. Sie zeigen jeden Hit auf den Server, vor jeder Analytics-Filterung. Wenn der Hoster die Logs zugänglich macht — per FTP, Backend oder SSH — bist du an der direkten Quelle.
Auf Linux- oder WSL-Systemen schnell mit grep:
zcat access_log_*.gz access_log 2>/dev/null \
| grep -E "(GPTBot|ChatGPT-User|ClaudeBot|Claude-Web|anthropic|PerplexityBot|Google-Extended|Applebot-Extended|meta-externalagent|CCBot)" \
| awk '{print $1, $9, substr($0, index($0,$12))}' \
| sort | uniq -c | sort -rn | head -30
Das listet IP, Statuscode und User-Agent-Fragment, sortiert nach Häufigkeit. Auffällige Statuscodes (403, 429, 503) bei einzelnen Bot-Identitäten zeigen, ob ein Bot durchgereicht und dann an anderer Stelle abgeworfen wurde.
Bei umfangreichen Logs lohnt das gezielte Hochladen an Claude oder ChatGPT zur Auswertung. Ein Prompt, der zuverlässig sauber strukturierte Ergebnisse liefert:
Ich habe Apache-Access-Logs einer Geschäfts-Website. Bitte analysiere folgende Punkte als Tabelle:
- Welche KI-Crawler haben die Seite besucht (GPTBot, ChatGPT-User, ClaudeBot, Claude-Web, anthropic-ai, PerplexityBot, Google-Extended, Applebot-Extended, meta-externalagent, CCBot)?
- Wie oft pro Bot, im Zeitraum der Logs?
- Welche Statuscodes haben diese Bots erhalten? Listing nach Bot und Code.
- Welche Pfade wurden besucht? Top-10 pro Bot.
- Auffälligkeiten — systematische 403/404, Crawl-Spitzen, Bot-Identitäten außerhalb der Liste?
Vor dem Hochladen IPs anonymisieren. IP-Adressen sind nach DSGVO personenbezogen, und auch wenn Crawler-IPs eher nicht zu Personen führen, ist die saubere Lösung, das letzte Oktett zu kürzen:
sed -E 's/([0-9]+\.[0-9]+\.[0-9]+\.)[0-9]+/\1xxx/g' access.log > access_anonym.log
Schritt 7 — robots.txt und llms.txt im Kontext
Erst nachdem die Erreichbarkeits-Schicht sauber ist, lohnt der Blick auf die Bot-Steuerung über robots.txt. Davor ist es Optimierung am verschlossenen Schaufenster.
robots.txt: Die typische Yoast-Default-robots.txt enthält ein Disallow: /wp-json/. Für die meisten Sites ist das egal, weil die KI-Bots HTML lesen. Wenn die Site allerdings strukturierte Inhalte über die WordPress-REST-API ausspielt — etwa für eigene MCP-Anbindungen oder ein Headless-Frontend — wird das zur Bremse.
Explizite Allow-Regeln für KI-Bots haben keine technische Wirkung, wo User-agent: * ohnehin Allow ist. Sie sind aber ein positives Signal für KI-Audits und für manche Crawl-Scoring-Modelle. In WordPress per Filter ergänzen, nicht in der virtuellen Yoast-robots.txt:
add_filter('robots_txt', function($output, $public) {
if ('1' != $public) {
return $output;
}
$ai = "\n# AI Crawlers - explicitly allowed\n";
foreach (['GPTBot', 'ChatGPT-User', 'ClaudeBot', 'Claude-Web',
'Google-Extended', 'PerplexityBot', 'Applebot-Extended'] as $bot) {
$ai .= "User-agent: {$bot}\nAllow: /\n\n";
}
return $output . $ai;
}, 10, 2);
Das Snippet gehört in ein Code-Snippet-Plugin (Code Snippets, WPCodeBox), nicht in die functions.php des Themes — sonst ist es beim nächsten Theme-Update weg.
llms.txt: Wenn vorhanden, sollte sie strukturiert sein: kurze Beschreibung, Hauptseiten als Markdown-Links, klare Sektionen. Wenn nicht vorhanden, ist sie kein blocker — aber ein lohnendes Add-On, sobald die Erreichbarkeit sauber ist.
Reihenfolge ist Pflicht
Die Versuchung in der KI-SEO-Beratung ist, mit dem Sichtbaren zu beginnen — Schema, llms.txt, Content-Restrukturierung, Authority. Das alles ist richtig und lohnt den Aufwand. Es ist aber wirkungslos, solange die Bots am Türsteher hängenbleiben.
Sinnvolle Reihenfolge:
- Erreichbarkeit (Schritte 1 bis 3)
- Diagnose-Ist-Stand (Schritte 4 bis 6)
- Optimierung (Schema, llms.txt, Content, Authority)
Wer Schritt 3 ohne 1 und 2 angeht, optimiert für ein Publikum, das gar nicht zuhören kann.
Was die Schicht-Trennung außerdem klar macht
Bot-Erreichbarkeit ist eine Infrastruktur-Frage, nicht eine SEO-Frage. Sie liegt im Verantwortungsbereich des Hosters und des Server-Setups, nicht im Marketing-Stack. Der saubere Weg ist, sie als eigenen Audit-Punkt zu führen und vor jeder inhaltlichen Optimierung zu klären — auch dann, wenn das Audit-Tool sie als „grün“ markiert.
Audit-Tools prüfen typischerweise mit ihrem eigenen Crawler-User-Agent, nicht mit GPTBot oder ClaudeBot. Ein Tool, das nicht explizit „GPTBot reachable: yes/no“ als eigenen Test ausweist, übersieht die Hoster-Sperre vollständig.
Quellen
- OpenAI: Bots und User-Agents — https://platform.openai.com/docs/bots
- Anthropic: Crawler-Dokumentation — https://support.anthropic.com/en/articles/8896518
- Perplexity: Bot-Übersicht — https://docs.perplexity.ai/guides/bots
- Google: Crawler-Liste — https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers
- Apple: Applebot-Dokumentation — https://support.apple.com/en-us/119829
Zum Autor
Sönke Schäfer berät seit über 25 Jahren norddeutsche KMU bei Datenarchitektur, Datenbank-Modernisierung und der Anbindung von KI an gewachsene Bestände. Sein Schwerpunkt liegt auf der Schnittstelle zwischen klassischer Infrastruktur und neuen KI-Werkzeugen — dort, wo „Struktur vor KI“ konkret wird.

