
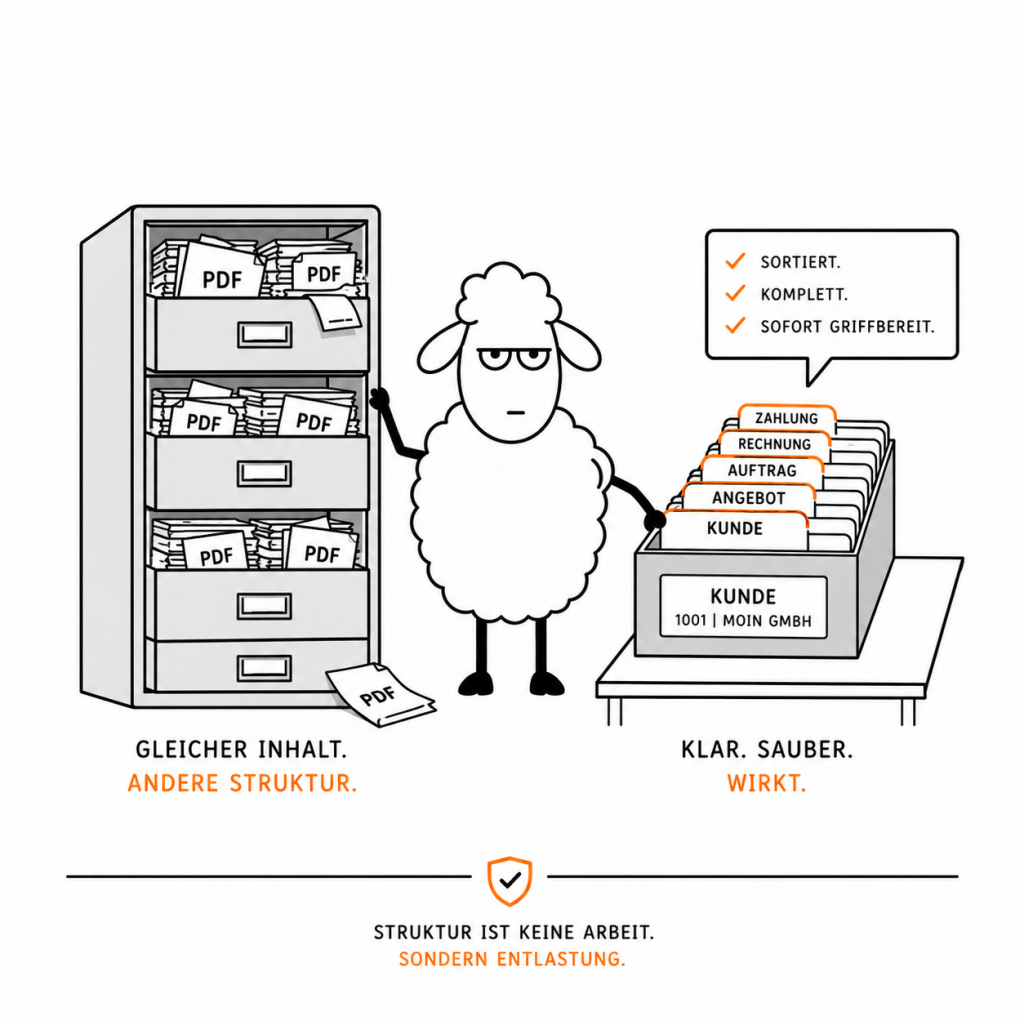
Gerade liegt bei einem Mittelständler die Entscheidung an, das komplette Firmenwissen in ein lokales KI-System zu laden. Der Plan klingt naheliegend: alle PDFs hochladen, fertig. Und weil ein großer Teil des Wissens in einer Datenbank steckt, soll die vorher als PDF exportiert und gleich mit hochgeladen werden.
Das ist der teuerste Weg zum schlechtesten Ergebnis. Nicht, weil die KI zu dumm wäre. Sondern weil PDF das falsche Format ist, um Daten für RAG aufzubereiten.
Das eigentliche Problem sitzt nicht im Modell
Wer ein lokales RAG-System wie AnythingLLM, LM Studio oder Ollama aufsetzt, kümmert sich meist intensiv um das Modell: Welches läuft auf der Hardware, wie viel Kontext, welche Quantisierung. Die Datenaufbereitung wird zur Nebensache erklärt — man kippt rein, was da ist.
Genau hier kippt die Qualität. RAG zerlegt jedes Dokument in Häppchen („Chunks“), wandelt die in Vektoren um und sucht bei einer Frage die passenden Häppchen heraus. Wie gut diese Häppchen geschnitten sind, hängt am Eingangsformat. Schlecht geschnittene Häppchen bedeuten schlechte Antworten — egal, wie gut das Modell ist.
Aus meiner Praxis im norddeutschen Mittelstand zeigt sich: Die Antwortqualität eines RAG-Systems wird zu einem überraschend großen Teil schon entschieden, bevor das Modell überhaupt eine Zeile sieht.
Daten für RAG aufbereiten heißt: Struktur erhalten, nicht Layout
PDF ist ein Druckformat. Es beschreibt, wo auf einer Seite welche Buchstaben stehen — nicht, was inhaltlich zusammengehört. Beim Auslesen passiert deshalb regelmäßig das hier:
- Mehrspaltiger Satz wird in falscher Lesereihenfolge zusammengewürfelt.
- Tabellen zerfallen, Spalten landen wild durcheinander.
- Kopf- und Fußzeilen, Seitenzahlen und Wasserzeichen rutschen als Rauschen in die Chunks.
- Eingescannte Seiten sind reine Bilder und brauchen erst OCR — mit eigenen Fehlern.
Eine als PDF exportierte Datenbankabfrage ist der Extremfall: Du nimmst sauber strukturierte Daten und presst sie in ein Format, das diese Struktur wieder zerstört. Die Maschine muss anschließend mühsam rekonstruieren, was vorher schon ordentlich vorlag.
Es gibt eine brauchbare Rangfolge fürs Mitnehmen, wenn es um Material für KI-Systeme geht:
strukturiertes Markdown / Plaintext > sauberes semantisches HTML > rohes oder JavaScript-lastiges HTML > PDF.
Markdown gewinnt aus zwei getrennten Gründen. Erstens der Token-Aufwand: Eine Überschrift ist ein #, eine Liste ein -, eine Tabelle ein paar |. Kaum Ballast. HTML schleppt für denselben Inhalt Tags, schließende Elemente, div-Verschachtelungen, Klassen und Inline-Styles mit — der Tokenizer zählt das alles mit, du bezahlst Layout-Müll. Zweitens die Schnitt-Qualität: Markdown hat verlässliche Grenzen. Eine Überschrift ist ein sauberer Schnittpunkt, eine Tabelle bleibt eine Tabelle.
Wichtig zur Einordnung, damit es nicht zu absolut klingt: Sauberes, semantisches HTML ist für KI durchaus brauchbar — es ist die Muttersprache des Webs. Das Problem sind verschachteltes JavaScript-HTML und eben PDF. Markdown ist nur die schlankere und zuverlässigere Variante.
Was Markdown und OKF eigentlich sind
Markdown ist ein leichtgewichtiges Textformat, das Struktur mit minimalen Sonderzeichen abbildet — lesbar für Menschen und für Maschinen, ohne Spezial-Software. Eine Markdown-Datei lässt sich in jedem Editor öffnen und gleichzeitig zuverlässig von einer KI verarbeiten.
Im November 2025 hat Google dazu das Open Knowledge Format (OKF) veröffentlicht — derzeit als Entwurf in Version 0.1. OKF ist eine schlanke Konvention, um Wissen als Verzeichnis von Markdown-Dateien mit YAML-Kopfzeile abzulegen, sodass sowohl Menschen als auch KI-Agenten es lesen und durchsuchen können. Keine zentrale Instanz, keine Pflicht-Software. Wer eine Datei mit cat anzeigen kann, kann OKF lesen.
Der Kern besteht aus wenigen Bausteinen: Jede .md-Datei beschreibt ein Konzept (eine Tabelle, eine Kennzahl, ein Prozess). Oben steht ein kleiner YAML-Block mit Feldern wie type (Pflicht), title, description und timestamp. Darunter folgt der Inhalt als normales Markdown, idealerweise mit einer # Schema-Überschrift und einer Tabelle. Verlinkt wird über normale Markdown-Links.
OKF ist nicht der einzige Ansatz dieser Art, und es ist auch keine technische Neuerung. Verwandt sind:
- llms.txt — eine Markdown-Datei im Wurzelverzeichnis einer Website, die einer KI die wichtigsten Inhalte strukturiert anbietet.
- Obsidian und Notion — persönliche Wissensspeicher auf Basis von Markdown mit Querverweisen.
- dbt docs und ähnliche „Metadata as Code“-Ansätze — Katalog-Metadaten direkt neben dem Code statt in einer separaten Datenbank.
- MCP (Model Context Protocol) — liegt auf einer anderen Ebene: Das ist die Tür zum Zugriff, nicht das Lagerformat. OKF und MCP konkurrieren nicht, sie ergänzen sich.
Der einzige echte Mehrwert von OKF ist, dass diese ohnehin verbreitete Praxis jetzt einen Namen, eine Spezifikation und einen Google-Stempel hat. Für die Praxis zählt nicht das Etikett, sondern die Haltung dahinter: Struktur vor KI.
Für die Entwickler: Eine Access-Abfrage als OKF-Markdown exportieren
Ab hier wird es technisch. Wen nicht der Code interessiert, sondern die Wirtschaftlichkeit, springt zum nächsten Abschnitt.
Der Punkt ist: Eine Datenbank ist bereits ein OKF-Bundle — sie weiß es nur noch nicht. Spalten, Datentypen, Beziehungen, Beschreibungen: Die Struktur, die ein RAG-System braucht, liegt längst im Schema. Statt sie über einen PDF-Export zu zerstören, exportiert man sie direkt als OKF-konformes Markdown.
Die folgende VBA-Funktion nimmt eine gespeicherte Access-Abfrage (oder Ad-hoc-SQL), setzt optional einen Parameter und schreibt das Ergebnis als OKF-Markdown-Datei: YAML-Frontmatter plus # Schema-Tabelle. Geschrieben wird per ADODB.Stream in UTF-8 — damit Lübeck auch Lübeck bleibt und nicht als Zeichensalat im Chunk landet. Die API-Deklaration für den Zeitstempel ist 32- und 64-Bit-sicher gehalten.
Option Compare Database
Option Explicit
' --- Windows-API für echten UTC-Zeitstempel (32/64-Bit-sicher) ---
Private Type SYSTEMTIME
wYear As Integer
wMonth As Integer
wDayOfWeek As Integer
wDay As Integer
wHour As Integer
wMinute As Integer
wSecond As Integer
wMilliseconds As Integer
End Type
#If VBA7 Then
Private Declare PtrSafe Sub GetSystemTime Lib "kernel32" (lpSystemTime As SYSTEMTIME)
#Else
Private Declare Sub GetSystemTime Lib "kernel32" (lpSystemTime As SYSTEMTIME)
#End If
'==============================================================
' ExportAbfrageAlsOKF
' Exportiert das Ergebnis einer (parametrisierten) Abfrage als
' OKF-konforme Markdown-Datei (Frontmatter + # Schema-Tabelle).
'
' sAbfrage : Name einer gespeicherten Abfrage ODER SQL-Text
' sZielDatei : vollständiger Pfad der .md-Zieldatei
' sType : OKF-Pflichtfeld, z. B. "Access Query"
' sTitel : Anzeigename
' sBeschreibung : optionaler Einzeiler
' sResource : optionale URI zur Quelle
' sTags : optional, kommagetrennt (z. B. "kunden, vertrieb")
' vParameter : optionaler Wert für den ersten Abfrageparameter
'
' Rückgabe: Anzahl exportierter Datensätze, -1 bei Fehler
'==============================================================
Public Function ExportAbfrageAlsOKF( _
ByVal sAbfrage As String, _
ByVal sZielDatei As String, _
ByVal sType As String, _
ByVal sTitel As String, _
Optional ByVal sBeschreibung As String = "", _
Optional ByVal sResource As String = "", _
Optional ByVal sTags As String = "", _
Optional ByVal vParameter As Variant) As Long
Dim db As DAO.Database
Dim qd As DAO.QueryDef
Dim rs As DAO.Recordset
Dim sb As String
Dim sLine As String
Dim i As Long, n As Long
Dim bTempQd As Boolean
On Error GoTo Fehler
Set db = CurrentDb
' Abfrage auflösen: gespeicherte Abfrage oder Ad-hoc-SQL
If QueryDefVorhanden(db, sAbfrage) Then
Set qd = db.QueryDefs(sAbfrage)
Else
Set qd = db.CreateQueryDef("", sAbfrage) ' temporär, nicht gespeichert
bTempQd = True
End If
' Parameter setzen, falls vorhanden und übergeben
If Not IsMissing(vParameter) Then
If qd.Parameters.Count > 0 Then qd.Parameters(0).Value = vParameter
End If
Set rs = qd.OpenRecordset(dbOpenSnapshot)
' --- YAML-Frontmatter (OKF, Abschnitt 4.1) ---
sb = "---" & vbLf
sb = sb & "type: " & sType & vbLf ' Pflichtfeld
sb = sb & "title: " & sTitel & vbLf
If Len(sBeschreibung) > 0 Then sb = sb & "description: " & sBeschreibung & vbLf
If Len(sResource) > 0 Then sb = sb & "resource: " & sResource & vbLf
If Len(sTags) > 0 Then sb = sb & "tags: [" & sTags & "]" & vbLf
sb = sb & "timestamp: " & ISO8601UTC() & vbLf
sb = sb & "---" & vbLf & vbLf
' --- Body: # Schema als Markdown-Tabelle (OKF, Abschnitt 4.2) ---
sb = sb & "# Schema" & vbLf & vbLf
' Kopfzeile aus Feldnamen
sLine = "|"
For i = 0 To rs.Fields.Count - 1
sLine = sLine & " " & rs.Fields(i).Name & " |"
Next i
sb = sb & sLine & vbLf
' Trennzeile
sLine = "|"
For i = 0 To rs.Fields.Count - 1
sLine = sLine & " --- |"
Next i
sb = sb & sLine & vbLf
' Datenzeilen
n = 0
Do While Not rs.EOF
sLine = "|"
For i = 0 To rs.Fields.Count - 1
sLine = sLine & " " & MDZelle(rs.Fields(i).Value) & " |"
Next i
sb = sb & sLine & vbLf
n = n + 1
rs.MoveNext
Loop
SchreibeUTF8 sZielDatei, sb
rs.Close
ExportAbfrageAlsOKF = n
Aufraeumen:
On Error Resume Next
If Not rs Is Nothing Then rs.Close
Set rs = Nothing
If bTempQd And Not qd Is Nothing Then qd.Close
Set qd = Nothing
Set db = Nothing
Exit Function
Fehler:
MsgBox "Export fehlgeschlagen: " & Err.Number & " - " & Err.Description, _
vbExclamation, "ExportAbfrageAlsOKF"
ExportAbfrageAlsOKF = -1
Resume Aufraeumen
End Function
' Prüft, ob eine gespeicherte Abfrage mit dem Namen existiert
Private Function QueryDefVorhanden(ByVal db As DAO.Database, ByVal sName As String) As Boolean
Dim qd As DAO.QueryDef
On Error Resume Next
Set qd = db.QueryDefs(sName)
QueryDefVorhanden = (Err.Number = 0) And (Not qd Is Nothing)
End Function
' Macht einen Feldwert tabellensicher: Null -> "", Pipe escapen, Umbrüche raus
Private Function MDZelle(ByVal v As Variant) As String
Dim s As String
If IsNull(v) Then MDZelle = "": Exit Function
s = CStr(v)
s = Replace(s, "|", "\|")
s = Replace(s, vbCrLf, " ")
s = Replace(s, vbCr, " ")
s = Replace(s, vbLf, " ")
MDZelle = Trim$(s)
End Function
' ISO-8601-Zeitstempel in UTC, z. B. 2026-06-13T09:30:00Z
Private Function ISO8601UTC() As String
Dim st As SYSTEMTIME
GetSystemTime st
ISO8601UTC = Format$(st.wYear, "0000") & "-" & Format$(st.wMonth, "00") & "-" & _
Format$(st.wDay, "00") & "T" & Format$(st.wHour, "00") & ":" & _
Format$(st.wMinute, "00") & ":" & Format$(st.wSecond, "00") & "Z"
End Function
' Schreibt Text als UTF-8 (late-bound, keine Referenz nötig)
Private Sub SchreibeUTF8(ByVal sPfad As String, ByVal sInhalt As String)
Dim stm As Object
Set stm = CreateObject("ADODB.Stream")
stm.Type = 2 ' adTypeText
stm.Charset = "utf-8"
stm.Open
stm.WriteText sInhalt
stm.SaveToFile sPfad, 2 ' adSaveCreateOverWrite
stm.Close
Set stm = Nothing
End Sub
Entscheidend ist die letzte Idee: Der Export erzeugt keine schöne Seite zum Ausdrucken, sondern eine maschinenlesbare Tabelle mit Kontext im Kopf. Genau das, was ein RAG-System braucht.
Die zugehörige Abfrage qry_KundenNachRegion deklariert ihren Parameter explizit, damit die Funktion ihn setzen kann:
PARAMETERS [prmRegion] Text(255);
SELECT KundenNr, Firma, Ort, Umsatz
FROM tblKunden
WHERE Region = [prmRegion] AND Aktiv = True;
Der Aufruf bleibt überschaubar:
Dim n As Long
n = ExportAbfrageAlsOKF( _
sAbfrage:="qry_KundenNachRegion", _
sZielDatei:="C:\okf-bundle\tables\kunden-ostholstein.md", _
sType:="Access Query", _
sTitel:="Kunden Region Ostholstein", _
sBeschreibung:="Aktive Kunden im Kreis Ostholstein, eine Zeile pro Kunde.", _
sResource:="access://Kundendb/qry_KundenNachRegion", _
sTags:="kunden, ostholstein, vertrieb", _
vParameter:="Ostholstein")
Debug.Print n & " Datensaetze exportiert."
Wer das pro Region, pro Standort oder pro Produktgruppe in einer Schleife laufen lässt, hat in wenigen Minuten ein ganzes OKF-Bundle aus der Datenbank gezogen — verlustfrei, durchsuchbar und versionierbar. Dasselbe Prinzip lässt sich für SQL Server über eine entsprechende Prozedur abbilden.
Wo der Ansatz an Grenzen stößt
Markdown löst nicht alles. Tabellarische Daten gehen sauber, lange Freitext-Verträge oder gescannte Altdokumente bleiben Handarbeit und brauchen weiterhin OCR. Die Metadaten im Kopf müssen jemand pflegen — ein guter description-Satz pro Datei kostet Zeit, zahlt sich aber bei jeder Abfrage aus. Und OKF ist Stand jetzt ein Entwurf in Version 0.1; wer darauf baut, baut auf etwas, das sich noch ändern kann. Für die eigene RAG-Aufbereitung ist das unkritisch, weil es ohnehin nur normale Markdown-Dateien sind. Ein kleiner Stolperstein am Rande: ADODB.Stream schreibt UTF-8 standardmäßig mit BOM — die meisten RAG-Parser stört das nicht, einzelne schon. Im Zweifel das BOM entfernen.
Was das für dich bedeutet, wenn du das nicht selbst baust
Die Struktur, die deine KI braucht, liegt seit Jahren in deiner Datenbank. Spalten, Beziehungen, Beschreibungen — alles da. Der Reflex, das vor dem KI-Projekt als PDF zu exportieren, vergräbt diese Struktur ausgerechnet in dem Moment, in dem du sie am dringendsten brauchst.
Für ein RAG-Projekt heißt das konkret: Bevor Budget in Hardware und Modelle fließt, lohnt eine Stunde Nachdenken über das Eingangsformat. Wer Datenbank-Inhalte strukturiert exportiert statt als PDF, bekommt bessere Antworten bei weniger Rechenaufwand — und spart sich die Enttäuschung, dass die teure KI „irgendwie nicht richtig funktioniert“.
Struktur vor KI ist kein Slogan. Es ist die Reihenfolge, in der ein RAG-Projekt gelingt oder scheitert.
Wenn du ein RAG-Projekt mit eigenen Daten planst
Wer vor der Entscheidung steht, wie das Firmenwissen in ein KI-System kommt, sollte das Eingangsformat klären, bevor das erste PDF hochgeladen wird. Wer sich das einmal anschauen lassen möchte, erreicht mich über sesoft.de/kontakt.
Quellen
- Open Knowledge Format (OKF), Spezifikation v0.1: github.com/GoogleCloudPlatform/knowledge-catalog
- Google Cloud Blog zur Einordnung des Formats: cloud.google.com/blog
- llms.txt — Vorschlag für KI-lesbare Website-Inhalte: llmstxt.org
- AnythingLLM, lokales RAG-System: anythingllm.com
Über den Autor
Sönke Schäfer ist selbstständiger IT-Berater und Datenarchitekt aus Sierksdorf in Ostholstein und betreut seit über 25 Jahren norddeutsche KMU. Sein Schwerpunkt liegt auf der Anbindung von KI an bestehende Datenbanken — Microsoft Access, VBA und SQL Server als Fundament, nicht als Altlast. Mehr unter Der Datenschäfer.
PS:
AnythingLLM kann SQL Server übrigens auch direkt — aber als Agent-Skill, nicht als RAG. Der SQL-Connector ist Text-to-SQL: Das Modell schaut sich per @agent die Tabellen an, formuliert daraus eine Abfrage und zieht die Zeilen live aus der Datenbank. Nichts davon wird eingebettet. Das ist der zweite Weg neben dem hier gezeigten Export — und beide haben ihren Platz: Für exakte, tagesaktuelle Auswertungen ist der SQL-Agent stark, für durchsuchbares Wissen neben Dokumenten der eingebettete Markdown-Export. Wichtig fürs Mitnehmen: PDF ist für beide Wege falsch. Beim RAG zerstört es die Struktur, beim SQL-Agenten ist es schlicht überflüssig, weil der die lebende Datenbank abfragt und gar keinen Export braucht. Wer den Agent-Weg geht, sollte ihm in jedem Fall einen nur-lesenden Datenbankbenutzer geben.

