
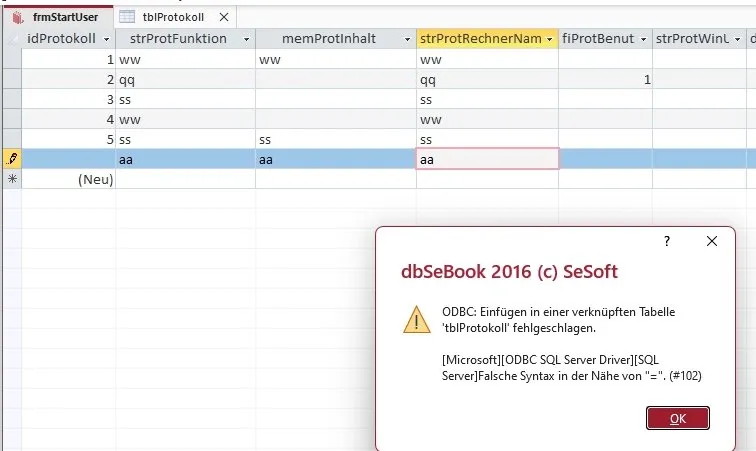
Bei einem Kundenprojekt aus den frühen 2000er Jahren — gewachsene Access-Anwendung, SQL-Server-Backend mit Linked Tables, seit fast zwei Jahrzehnten produktiv im Einsatz — knallte plötzlich jeder INSERT in eine Protokoll-Tabelle. Vorher: läuft. Nach einer kleinen Anpassung am Schema: „Falsche Syntax in der Nähe von ‚=‘. (#102)“. Die Spalte leer lassen reichte, dann ging der INSERT durch. Sobald Inhalt rein sollte, war Schluss.
Die Auflösung bestand am Ende aus zwei Teilen, die zusammenwirken mussten: ein Treiber-Update und eine Datentyp-Migration. Einzeln hätte keiner der beiden Schritte gereicht. Im Schlepptau lief noch ein dritter Punkt mit, der zwar nicht akut war, aber zur gleichen Generation Altlasten gehört. Drei Relikte aus der Frühzeit von SQL Server, die in Access-/SQL-Server-Bestandsanwendungen typischerweise gemeinsam auftreten.
Relikt 1: Der Treiber heißt nicht „SQL Server“
Die Fehlermeldung verriet den Kern, wenn man genau hinsah:
[Microsoft][ODBC SQL Server Driver][SQL Server]
Falsche Syntax in der Nähe von "=". (#102)
[ODBC SQL Server Driver] ist nicht „der ODBC-Treiber für SQL Server“. Das ist der uralte Microsoft-Treiber (sqlsrv32.dll), Bestandteil von Windows seit NT, seit 2005 nicht mehr weiterentwickelt. Er kennt kein VARCHAR(MAX), kein NVARCHAR(MAX), kein XML, kein DATE, kein DATETIME2. Für ihn endet die Welt bei TEXT und IMAGE.
Aktuelle Treiber melden sich anders. Driver 17 sagt [ODBC Driver 17 for SQL Server], Driver 18 sagt [ODBC Driver 18 for SQL Server]. Wer in einer Fehlermeldung nur [ODBC SQL Server Driver] ohne Versionsnummer sieht, hat den Steinzeit-Treiber im Einsatz.
Beim Kundenprojekt war die DSN seit Jahren gegen den alten „SQL Server“-Treiber konfiguriert. Solange im Backend nur TEXT und Standardtypen lagen, fiel das nicht auf — der Treiber kannte alles, was die Tabellen anboten. Der Wechsel auf Driver 18 war daher unausweichlich, sobald moderne Datentypen ins Spiel kamen.
Dabei drei Stolperfallen, die jede für sich Stunden kosten kann:
Driver 18 hat eine Encryption-Falle. Default ist Encrypt=Mandatory. Auf einem SQL Server Express ohne TLS-Zertifikat scheitert das. In der DSN-Konfiguration die Verbindungsverschlüsselung explizit auf optional setzen, oder bei DSN-less-Verbindungen direkt in den Connect-String schreiben:
Encrypt=Optional;TrustServerCertificate=Yes;
32-Bit und 64-Bit haben getrennte DSN-Listen. Bei 32-Bit-Access den 32-Bit-Manager (C:\Windows\SysWOW64\odbcad32.exe), bei 64-Bit-Access den 64-Bit-Manager (C:\Windows\System32\odbcad32.exe) — die Pfade sind genau anders rum, als man intuitiv denken würde. Eine DSN, die unter dem falschen Manager angelegt wurde, ist in Access schlicht unsichtbar.
DSN-Namen exakt schreiben. Eine Randbeobachtung aus dem Projekt: Beim Neuanlegen einer DSN unter leicht abweichender Schreibweise (klein-d statt groß-D im Namen) griff der ODBC-Manager auf einen Default zurück und der wiederum war der alte Treiber. Wer eine DSN umbaut, sollte sie unter exakt demselben Namen wieder aufbauen, wie der gespeicherte Connect-String der verlinkten Tabelle ihn vorgibt. Nicht jedes Windows reagiert sensibel auf Groß-/Kleinschreibung in DSN-Namen, aber wenn es passiert, sucht man lange.
Relikt 2: TEXT, NTEXT, IMAGE — die Zombie-Datentypen
TEXT, NTEXT und IMAGE sind seit SQL Server 2005 als deprecated markiert. Microsoft schreibt seit 20 Jahren in der Doku, dass sie „in einer zukünftigen Version“ entfernt werden. Sie sind immer noch da, weil zu viele Bestandsanwendungen darauf bauen — aber jede neue Tabelle sollte die LOB-Nachfolger nutzen: VARCHAR(MAX), NVARCHAR(MAX), VARBINARY(MAX).
Praktisch relevant ist der Unterschied an mehreren Stellen. Auf TEXT funktionieren viele Standard-Stringfunktionen schlicht nicht — LEN(), LEFT(), + '...' zur Konkatenation, LIKE mit Wildcard-Suche im Indexkontext. Stattdessen brauchst du DATALENGTH(), SUBSTRING(), READTEXT, WRITETEXT. Auf VARCHAR(MAX) läuft alles, was auch auf VARCHAR(255) läuft. Wer also moderne Stored Procedures, Views oder Computed Columns über bestehende Daten legen will, kommt an einer Migration nicht vorbei.
Im konkreten Projekt war die Migration sogar selbst der Auslöser des Treiber-Problems aus Relikt 1: Auf der TEXT-Spalte lief die Anwendung fast 20 Jahre stabil. Erst als die Spalte auf VARCHAR(MAX) umgestellt wurde, kam der alte ODBC-Treiber an seine Grenzen — er kennt den Datentyp nicht und baut beim INSERT ein fehlerhaftes Re-Fetch-Statement zusammen. Treiber-Update und Datentyp-Migration mussten beide passieren, sonst hätte der eine den anderen nicht mehr aufgefangen.
Wer wissen will, wo in einer SQL-Server-Datenbank noch deprecated LOB-Typen schlummern, kann das mit einer einfachen Abfrage gegen INFORMATION_SCHEMA herausfinden. Der folgende Block listet alle Spalten mit TEXT, NTEXT oder IMAGE und gleich den passenden Migrationspfad:
SELECT
TABLE_SCHEMA AS Schema_,
TABLE_NAME AS Tabelle,
COLUMN_NAME AS Spalte,
DATA_TYPE AS Aktueller_Typ,
CASE DATA_TYPE
WHEN 'text' THEN 'VARCHAR(MAX)'
WHEN 'ntext' THEN 'NVARCHAR(MAX)'
WHEN 'image' THEN 'VARBINARY(MAX)'
END AS Empfohlener_Typ,
IS_NULLABLE AS Nullable
FROM INFORMATION_SCHEMA.COLUMNS
WHERE DATA_TYPE IN ('text', 'ntext', 'image')
ORDER BY TABLE_SCHEMA, TABLE_NAME, ORDINAL_POSITION;
Die Migration einer einzelnen Spalte ist mit ALTER TABLE … ALTER COLUMN direkt möglich, solange keine Constraints, Trigger oder Volltextindizes im Weg sind. Für eine TEXT-Spalte sieht der ALTER so aus:
ALTER TABLE dbo.tblProtokoll
ALTER COLUMN memProtInhalt VARCHAR(MAX) NULL;
GO
Wichtig dabei: TEXT-Daten liegen in separaten Pages, referenziert über Pointer aus der Hauptzeile. SQL Server muss bei der Konvertierung physisch umkopieren. Bei großen Tabellen also nicht im Tagesgeschäft, sondern in einem Wartungsfenster ausführen, gegebenenfalls mit Logfile-Beobachtung. Im Anschluss sp_spaceused prüfen — meistens fällt die Tabellengröße deutlich, weil die separaten LOB-Pages nicht mehr genutzt werden.
Für eine ganze Datenbank lohnt sich ein generierendes Skript, das einem die ALTER-Statements vorbereitet. Es sucht alle deprecated Typen und gibt fertige Statements zur Übernahme aus:
SELECT
'ALTER TABLE [' + TABLE_SCHEMA + '].[' + TABLE_NAME + '] ' +
'ALTER COLUMN [' + COLUMN_NAME + '] ' +
CASE DATA_TYPE
WHEN 'text' THEN 'VARCHAR(MAX)'
WHEN 'ntext' THEN 'NVARCHAR(MAX)'
WHEN 'image' THEN 'VARBINARY(MAX)'
END +
CASE WHEN IS_NULLABLE = 'YES' THEN ' NULL' ELSE ' NOT NULL' END +
';' AS AlterStatement
FROM INFORMATION_SCHEMA.COLUMNS
WHERE DATA_TYPE IN ('text', 'ntext', 'image')
ORDER BY TABLE_SCHEMA, TABLE_NAME, ORDINAL_POSITION;
Vor dem Ausführen die Treffer einmal sichten und prüfen, ob auf der jeweiligen Spalte ein Volltextindex liegt, ein Default-Constraint mit ungewöhnlicher Definition oder ein Trigger, der mit dem alten Datentyp arbeitet. In den meisten KMU-Datenbanken sind diese Sonderfälle selten, aber lieber einmal kontrolliert als hinterher debuggt.
Nach dem ALTER müssen die verlinkten Tabellen in Access neu verknüpft werden, sonst arbeitet Access weiter mit dem gecachten alten Schema. Das ist die häufigste Stolperfalle nach einer Datentyp-Migration: Auf SQL-Server-Seite alles sauber, in Access funktioniert trotzdem nichts.
Relikt 3: timestamp heißt heute rowversion — aber nur im Namen
Die Spalte rowversion ist Pflicht für jede Tabelle, die aus Access über Linked Tables beschrieben wird. Sie verhindert, dass Access mit der Meldung „Datensatz wurde geändert von einem anderen Benutzer …“ in den Schreibkonflikt läuft, gibt dem ODBC-Treiber einen sauberen Wiederfindungs-Kandidaten nach IDENTITY-Inserts und kostet 8 Bytes pro Zeile.
Was viele nicht wissen: rowversion und timestamp sind in SQL Server derselbe Datentyp. Beide haben die system_type_id = 189, beide werden bei jedem Schreibvorgang automatisch auf einen monoton steigenden Datenbank-Wert gesetzt, beide verhalten sich gegenüber Access und ODBC identisch. timestamp ist nur das ältere Synonym, das Microsoft seit Jahren als deprecated markiert — primär aus Klarheits-Gründen, weil der Name irreführend ist. Der ANSI-SQL-Standard reserviert timestamp für etwas, das in SQL Server datetime2 heißt.
Konsequenz für Bestandsdatenbanken: Wer timestamp-Spalten hat, kann sie ruhig liegen lassen. Sie verhalten sich exakt wie rowversion. Ein ALTER COLUMN von timestamp auf rowversion ist gar nicht möglich — gleicher Typ, kein Parser-Pfad. Ein DROP/ADD wäre theoretisch machbar, würde aber alle Werte neu erzeugen. Was wiederum jeden Client zerschießt, der gerade einen rowversion-Wert gecached hat, um beim nächsten UPDATE auf Konflikte zu prüfen — also genau den Mechanismus, für den die Spalte da ist. Aufwand und Risiko ohne funktionalen Gewinn.
Die saubere Regel lautet daher: Bei neuen Tabellen rowversion schreiben, bei bestehenden timestamp stehenlassen. Die offizielle Microsoft-Empfehlung läuft seit Jahren genau in diese Richtung.
Wer prüfen will, welche Tabellen überhaupt schon eine Versions-Spalte haben (egal ob unter dem Namen timestamp oder rowversion), hilft sich mit einer Abfrage gegen sys.columns:
SELECT
s.name AS Schema_,
t.name AS Tabelle,
c.name AS Spalte
FROM sys.tables t
JOIN sys.schemas s ON s.schema_id = t.schema_id
LEFT JOIN sys.columns c
ON c.object_id = t.object_id
AND c.system_type_id = TYPE_ID('timestamp')
ORDER BY s.name, t.name;
Tabellen ohne Treffer in c.name haben noch keine rowversion. Wer sie aus Access beschreibt, sollte sie ergänzen. Der ALTER ist trivial:
ALTER TABLE dbo.tblProtokoll
ADD dtmTimestamp rowversion NOT NULL;
GO
Danach in Access die Tabellen-Verlinkung erneuern — wie bei jeder Schemaänderung.
Was das in Summe bedeutet
Die drei Relikte hängen zusammen, weil sie aus derselben Ära stammen — der Zeit vor SQL Server 2005, als TEXT, IMAGE, timestamp und der ursprüngliche „SQL Server“-Treiber Stand der Technik waren. In gewachsenen Access-Frontends mit langjährigem SQL-Server-Backend findest du oft alle drei: deprecated Spalten in den Tabellen, deprecated Spaltennamen für die Versionierung, deprecated Treiber im Connect-String. Solange nichts geändert wird, läuft das jahrelang stabil. Sobald jemand modernisiert — sei es nur eine einzelne Spalte — kommen die Inkonsistenzen ans Licht.
Eine einfache Reihenfolge für die Aufräumaktion: Erst der Treiber, dann die Datentypen, dann die rowversion-Spalten ergänzen. Treiber zuerst, weil ohne Driver 17 oder 18 jede VARCHAR(MAX)-Konvertierung sofort zu Fehlern führt. Datentypen zweitens, weil sie die fachliche Modernisierung sind. Die rowversion-Spalten am Ende, weil sie auf das saubere neue Schema aufsetzen und Access-Konflikte für die Zukunft minimieren.
Eine ehrliche Einschränkung: Wer eine Access-Anwendung mit 200 Linked Tables erbt, baut das nicht in einem Wochenende um. Die Skripte oben sind generisch, aber jede produktive Datenbank hat ihre Sonderfälle — Volltextindizes auf TEXT-Spalten, Trigger, die mit READTEXT arbeiten, Replikationsketten, in denen das Schema nicht frei änderbar ist. Vor der Massenkonvertierung steht immer ein Probedurchlauf in einer Kopie und ein Blick auf die Constraint-Landschaft. Das ist kein Hexenwerk, aber es kostet Zeit, die in Sprint-Planungen gerne unterschätzt wird.
Übersetzung für nicht-technische Leser
Wer hier mitliest, ohne selbst SQL Server zu administrieren: Der Kern der Geschichte ist, dass Software, die seit zehn oder fünfzehn Jahren stabil läuft, nicht automatisch „modern“ ist. Im Hintergrund stecken Treiber und Datentypen aus den Anfangsjahren, die noch funktionieren, aber bei jedem Modernisierungsschritt kleine Stolperfallen aufstellen. Wer als KMU eine gewachsene Access-/SQL-Server-Lösung hat und überlegt, sie auszubauen — neue Felder, größere Texte, KI-Anbindung — sollte den Treiber- und Datentyp-Stand zuerst prüfen lassen. Drei Stunden Bestandsaufnahme ersparen drei Tage Fehlersuche im Echtbetrieb.
Wer eine ältere Access-/SQL-Server-Anwendung im Bestand hat und vor einer Modernisierung steht — egal ob Datentyp-Aufräumung, Migration auf SQL Server Express 2022, oder Anbindung an externe Systeme — kann die Bestandsaufnahme über sesoft.de/kontakt anstoßen. Das Erstgespräch klärt, ob die drei Relikte aus diesem Beitrag bei dir noch im System sitzen und wie groß der Aufwand realistisch ist.
Quellen und weiterführend
- Microsoft Docs: Deprecated Database Engine Features in SQL Server
- Microsoft Docs: ntext, text, and image (Transact-SQL)
- Microsoft Docs: rowversion (Transact-SQL)
- Microsoft Download Center: Microsoft ODBC Driver for SQL Server
Über den Autor
Sönke Schäfer ist selbstständiger IT-Berater und Datenarchitekt in Ostholstein (Neustadt in Holstein, Schleswig-Holstein) und arbeitet seit über 25 Jahren mit Microsoft Access, VBA und SQL Server. Sein Schwerpunkt liegt auf der Modernisierung gewachsener KMU-Datenbanken — von der Datentyp-Aufräumung über ETL-Strecken bis zur SQL-Server-Anbindung an moderne Frontends. Mehr zum Autor: Sönke Schäfer
